.svg)
The Enterprise AI Safety Checklist: 25 Questions to Ask Before You Deploy a GenAI Assistant

Privacy and security is critical to successfully deploying AI platforms, programs, and processes. The bad news: you're increasing your exposure. The good news: a lot of AI risk is predictable and preventable if you ask the right questions before you flip the switch.
The fastest way to lose trust in AI is to ship it too early.
A single confidently wrong answer about a safety step, compliance rule, or customer entitlement can undo months of internal goodwill—and in regulated environments, it can also invite auditors, fines, or worse.
The good news: a lot of AI risk is predictable and preventable if you ask the right questions before you flip the switch.
This checklist gives you 25 questions to ask vendors (and your own team) before you deploy a genAI assistant to customers or employees. It’s written for people living at the intersection of support, operations, risk, and IT...where AI is exciting, but getting it wrong is not an option.
We’ll put special emphasis on an area that’s often overlooked: knowledge quality and governance, not just model choice.
Section 1: Data Privacy & Isolation
Start with the basics: where does your data live, who can see it, and what’s being done with it?
Does this system train on my data, now or in the future?
- Are my prompts, completions, or documents used to train shared models?
- Can we opt out and verify that?
Can I run this in a private, isolated environment (tenant, VPC, or on-prem)?
- Is my data logically and/or physically separated from other customers?
- Is there a “walled garden” or private workspace mode?
What data leaves the environment when we ask a question?
- Do document snippets or embeddings ever leave our private boundary?
- Is any PII, PHI, or proprietary content exposed to external services?
How is data encrypted at rest and in transit?
- Which encryption standards are used?
- Are keys customer-managed or vendor-managed?
What’s your incident response process if there’s a data exposure?
- Notification timelines, responsibilities, and forensics capabilities
- Past incidents and lessons learned (if any)
If a vendor can’t answer these clearly, you’re not shopping for enterprise AI. You’re shopping for a cool demo.
Section 2: Knowledge Quality & Grounding
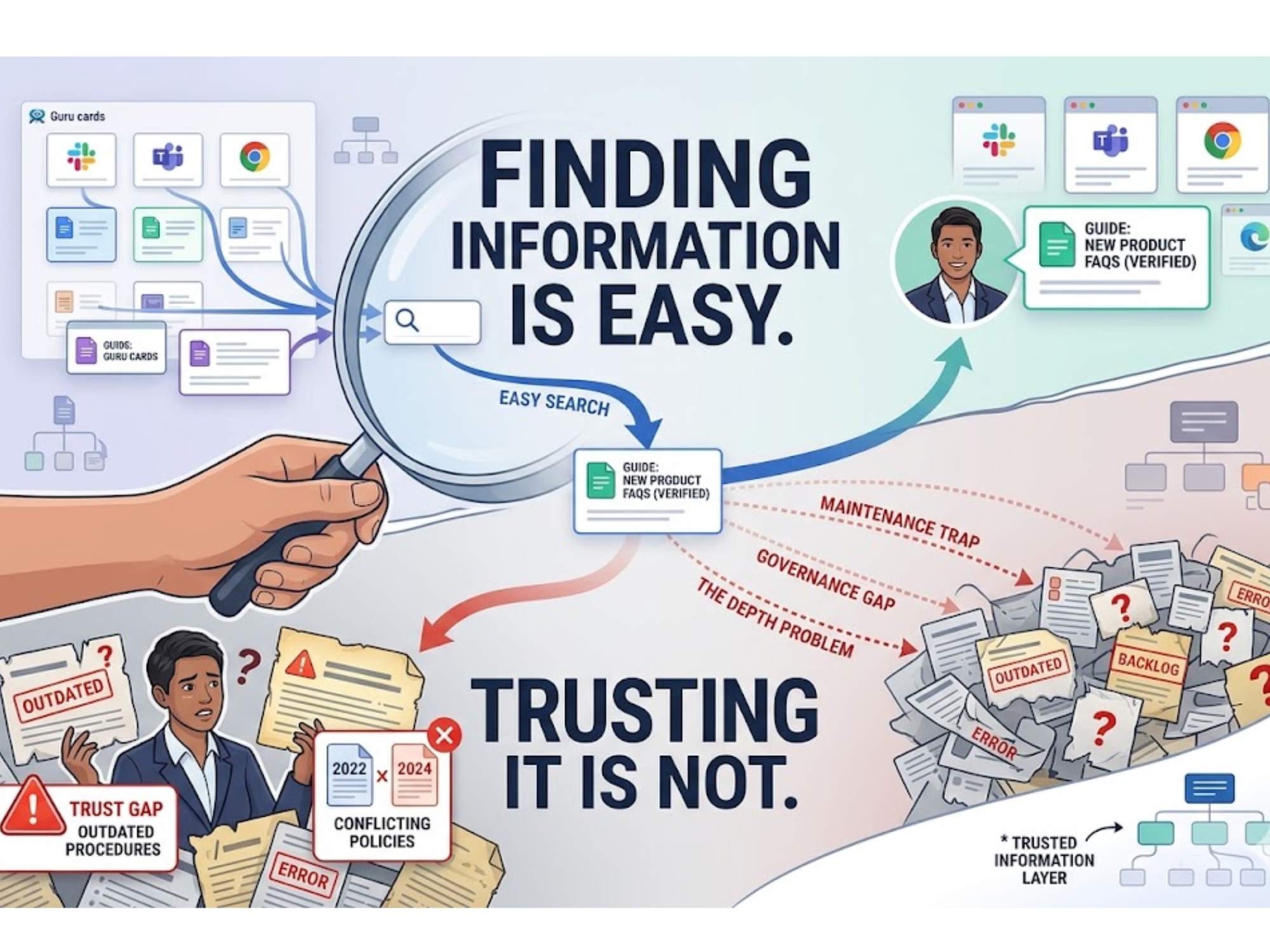
Most AI horror stories aren’t about raw model capability. They’re about what the model was (or wasn’t) grounded in.
How does the assistant decide what knowledge to use when answering a question?
- Is it just vector search over chunks, or is there a structured knowledge layer?
- Does it understand entities, relationships, and versions?
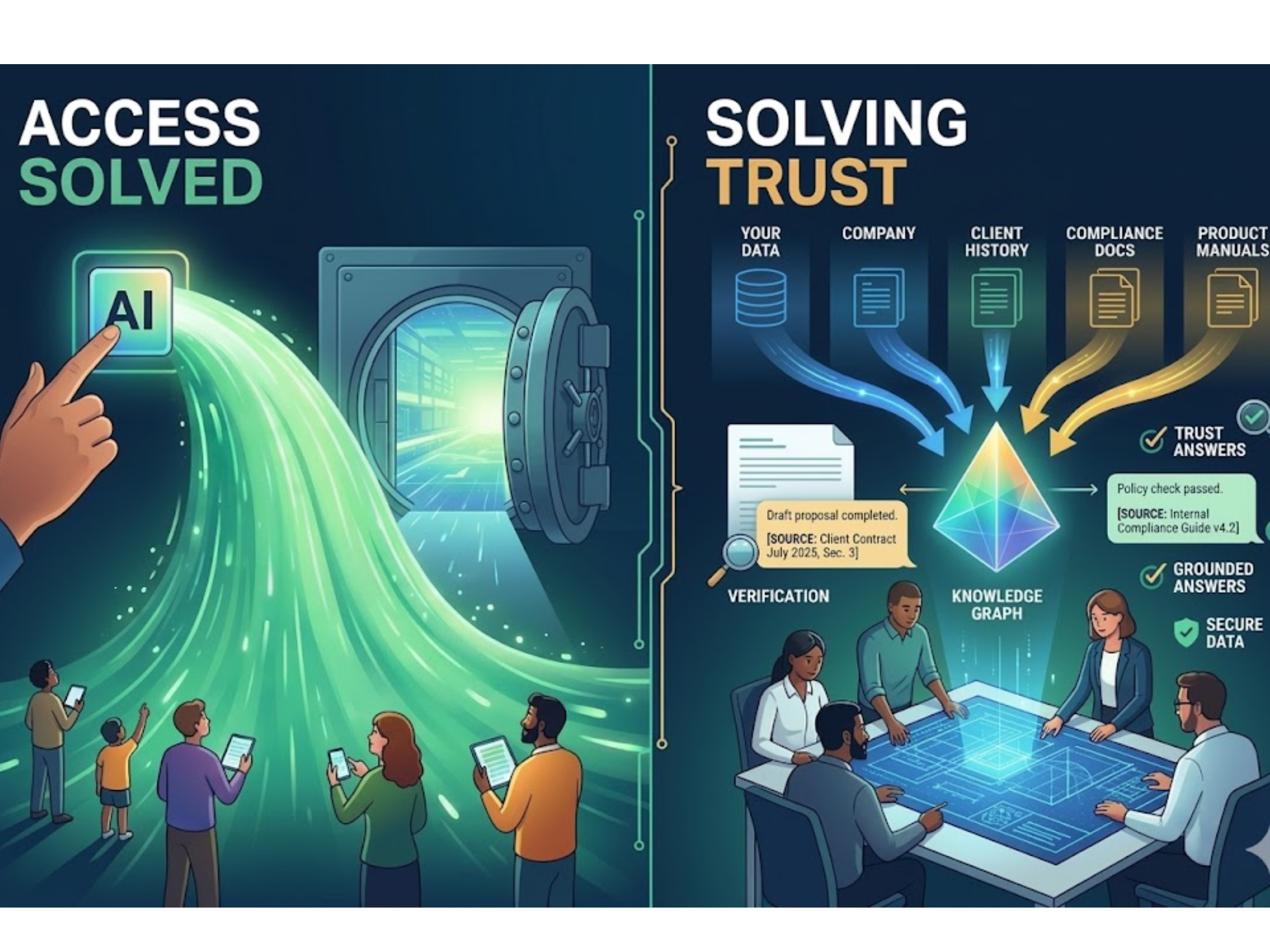
Can the system cite its sources for every answer?
- Are citations mandatory or optional?
- Can users click through to see the exact passages used?
How does the system handle conflicting documents?
- If two SOPs disagree, which one wins and why?
- Can you mark certain docs as authoritative or deprecated?
Can we restrict the assistant to only use approved content?
- E.g., only documents with a specific status, owner, or effective date
- Can draft content be explicitly excluded from answers?
What happens when the assistant doesn’t know the answer?
- Does it clearly say “I don’t know” or does it guess?
- Are there fallback workflows (e.g., escalate to human, suggest related docs)?
This is where a knowledge engine like Implicit is fundamentally different from pointing an LLM at a folder. If the vendor can’t show grounded, cited answers and a clear policy for “I don’t know,” that’s a red flag.
Section 3: Access Control & Permissions
An AI helper is effectively “search + reasoning + summarization.” If it ignores permissions, it’s a very smart data leak.
Does the assistant respect existing access controls and roles?
- Is there integration with your identity provider (SSO, SAML, SCIM)?
- Does retrieval filter content based on the user’s role and group membership?
Can we define fine-grained access rules for specific knowledge domains?
- E.g., “Finance procedures only visible to Finance,” “PHI only to clinicians”
- Can we mix public, internal, and highly restricted knowledge?
Is permission enforcement done at retrieval time or just in the UI?
- If someone hits the API directly, do the same rules apply?
- Are there protections against “prompt injection” attempting to bypass rules?
Can we prevent specific topics from being discussed altogether?
- E.g., “Never give legal advice,” “Never surface security architecture diagrams”
- Are these enforced in retrieval, generation, or both?
Can we audit who accessed what via the assistant?
- Logs that tie questions and answers back to individual users
- Ability to see what content was retrieved to answer a question
If permissions are only enforced in the frontend widget, assume someone will find a way around it.
Section 4: Auditability & Compliance
If your AI can’t be audited, it won’t survive long in finance, healthcare, aviation, or any other regulated environment.
Do you log all questions, answers, and underlying retrievals?
- Can we see which documents and snippets were used to formulate each answer?
- Can we export or query this data for internal audits?
Can we filter or redact sensitive information in logs?
- Ability to avoid storing raw PHI/PII where not appropriate
- Configurable retention policies
Can we replay “what the AI knew” at a point in time?
- Support for versioning and temporal queries
- Useful for incident investigations and regulatory reviews
What compliance frameworks do you support or align with?
- SOC 2, ISO 27001, HIPAA, GDPR, FedRAMP, etc.
- Are there clear roadmaps and evidence, not just “we’re working on it”?
Can we generate reports that show AI usage and risk indicators?
- Top categories of questions, answer quality metrics
- Escalation rates, override actions, and manual corrections
Without auditability, you can’t truly claim control. You only have influence.
Section 5: Change Management & Versioning
Your knowledge isn’t static. Products ship, procedures change, regulations update. Your AI needs to keep up safely.
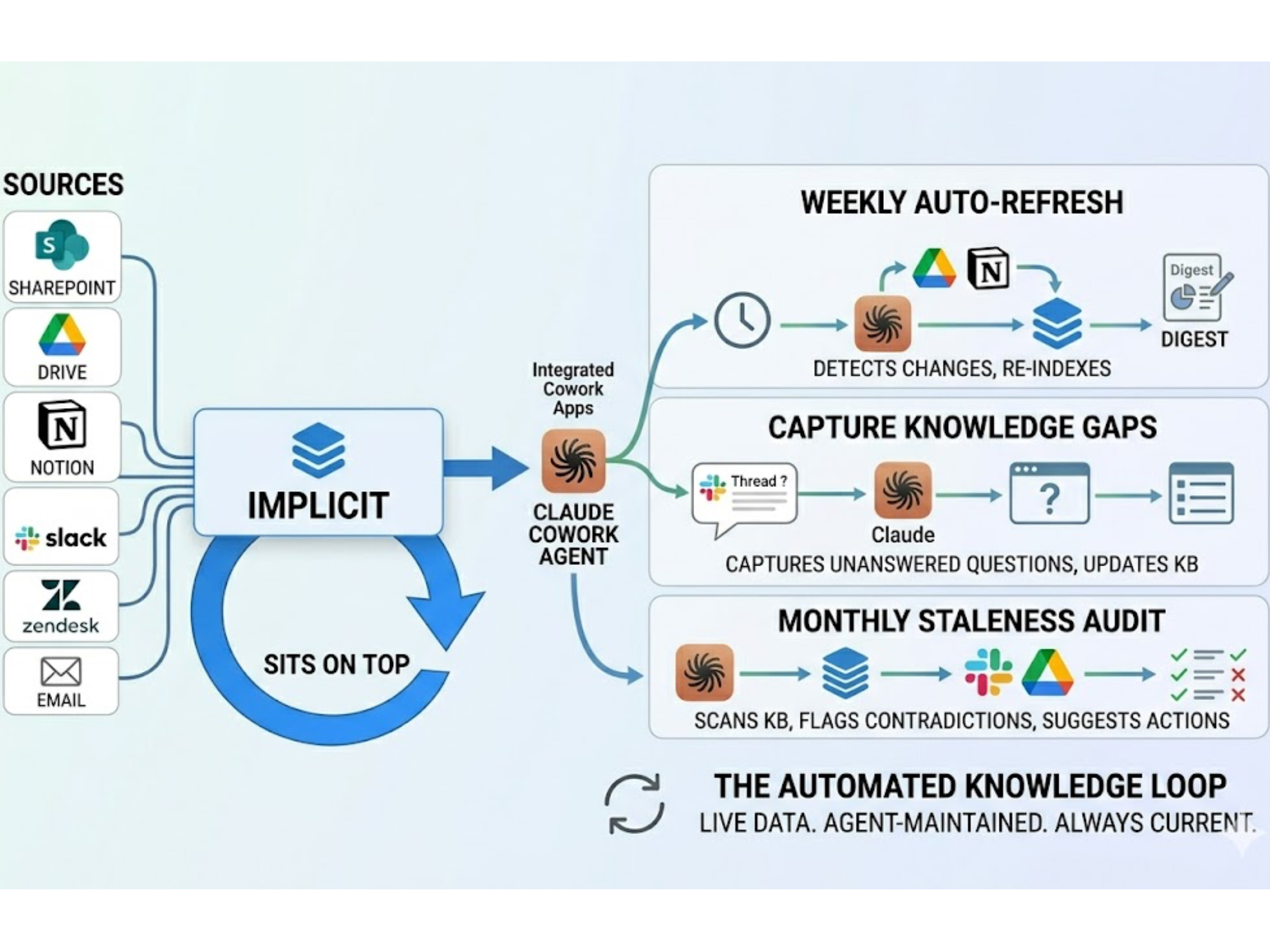
How are content updates propagated into the AI’s knowledge?
- Is there an ingestion schedule or real-time sync?
- How soon after a change does it affect answers?
Can we control which versions of documents the assistant uses?
- Draft vs in-review vs approved vs deprecated
- Ability to roll back to prior versions if needed
Is there a human-in-the-loop process for reviewing new or changed knowledge?
- Can SMEs review and approve how content is categorized or interpreted?
- Is there a workflow for suggesting new knowledge based on gaps?
How does the system surface emerging knowledge gaps?
- E.g., repeated “I don’t know” on a topic
- Clusters of escalations around new issues or releases
If your AI doesn’t evolve with your knowledge, it doesn’t stay “accurate”; it just becomes quietly wrong over time.
Section 6: Operational Readiness & Ownership
Finally, treat your AI assistant like any other critical system: it needs owners, SLAs, and a plan for when things go sideways.
Who owns this system internally, and what are the SLAs?
- Clear ownership across business, IT, and risk
- Defined uptime, response expectations, and escalation paths
What’s the rollback or kill switch if something goes wrong?
- Can we instantly disable certain capabilities or surfaces?
- Can we restrict the assistant to “read-only search and citations” mode?
How will we measure success and safety over time?
- Accuracy, containment, escalation rate, CSAT, time-to-resolution
- Complaints, incident counts, compliance findings
(Yes, we’re sneaking in 27 questions. “25” just looks nicer in a headline.)
How a Knowledge-First Approach Changes the Risk Equation
A lot of AI risk checklists focus almost entirely on the model: which one, from whom, with what parameters.
Don't get me wrong. That does matter, but if the underlying knowledge is unmanaged, unstructured, and ungoverned, you’re still rolling the dice.
A knowledge-first approach shifts the focus to:
- A private, structured knowledge layer as the source of truth
- Graph-based grounding (GraphRAG) with citations, not just semantic search
- Governance and approvals baked into the knowledge itself
- Auditability and versioning so you can prove what happened and when
That’s how you move from “We hope this works” to “We can show you exactly why this answer was given and which approved sources it used.”
Use This Checklist in Your Next Vendor (or Internal) Review
You can use these questions as:
- A vendor evaluation script for any AI support/copilot product
- A readiness checklist for internal AI projects
- A way to align legal, security, IT, and business teams around the same concerns
Print it, steal it, adapt it, argue with it...just please don’t skip it.
Because the difference between a neat AI demo and a production-ready assistant isn’t how flashy the UI looks. It’s whether you’ve taken the time to build and govern the knowledge and safeguards underneath it.