.svg)
RAG Is Good. GraphRAG + a Taxonomy-Driven Graph Wins
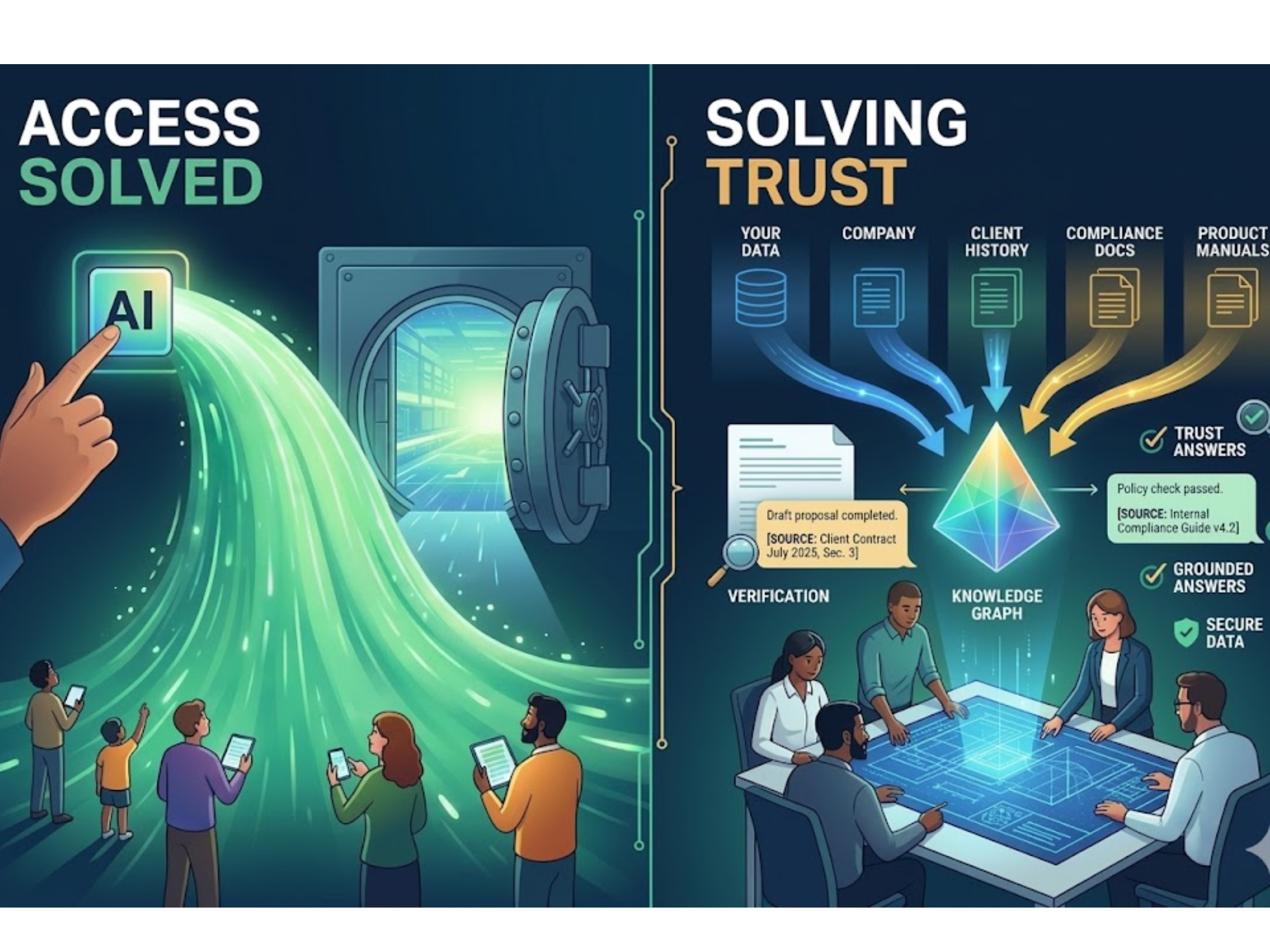
Accuracy isn’t a model problem, it’s a knowledge problem. The teams who win govern language and relationships, then let retrieval do surgical work.
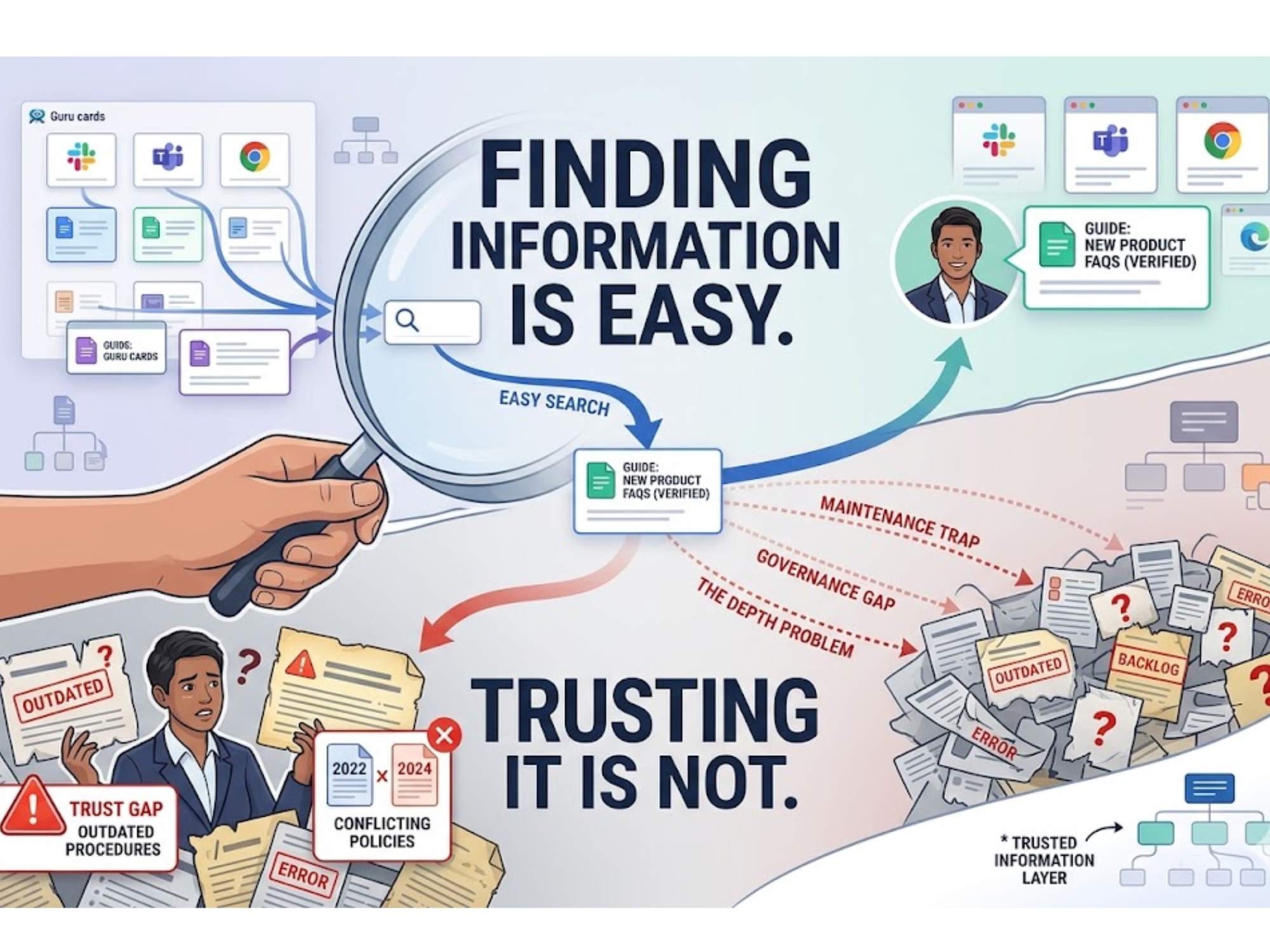
The symptom you’re blaming on AI (but shouldn’t)
“My bot hallucinated.”
Translation: your ontology drifted, your taxonomy splintered, and your corpus contradicted itself twelve different ways. Models aren’t mind readers, they’re pattern finishers. If your inputs are ambiguous and your labels are inconsistent, your answers will be, too.
The shift: From document hoarding to domain modeling
Classic RAG finds “relevant” chunks. That’s good.
GraphRAG maps how concepts relate: products → versions → parts → procedures → roles. Plus, it understands how language varies across teams and time. That’s better.
Add a Taxonomy-Driven Graph (TDG) and you finally govern the language itself:
- “Firmware v1.3,” “legacy firmware,” and “F1.3” resolve to the same entity.
- “Reset,” “reboot,” and “power cycle” normalize to one defined action.
- “Enterprise Plus” and “E+” point to the same SKU, versioned through releases.
Now retrieval routes to the right passages, assembles the right steps, and cites the canonical sources, every time.
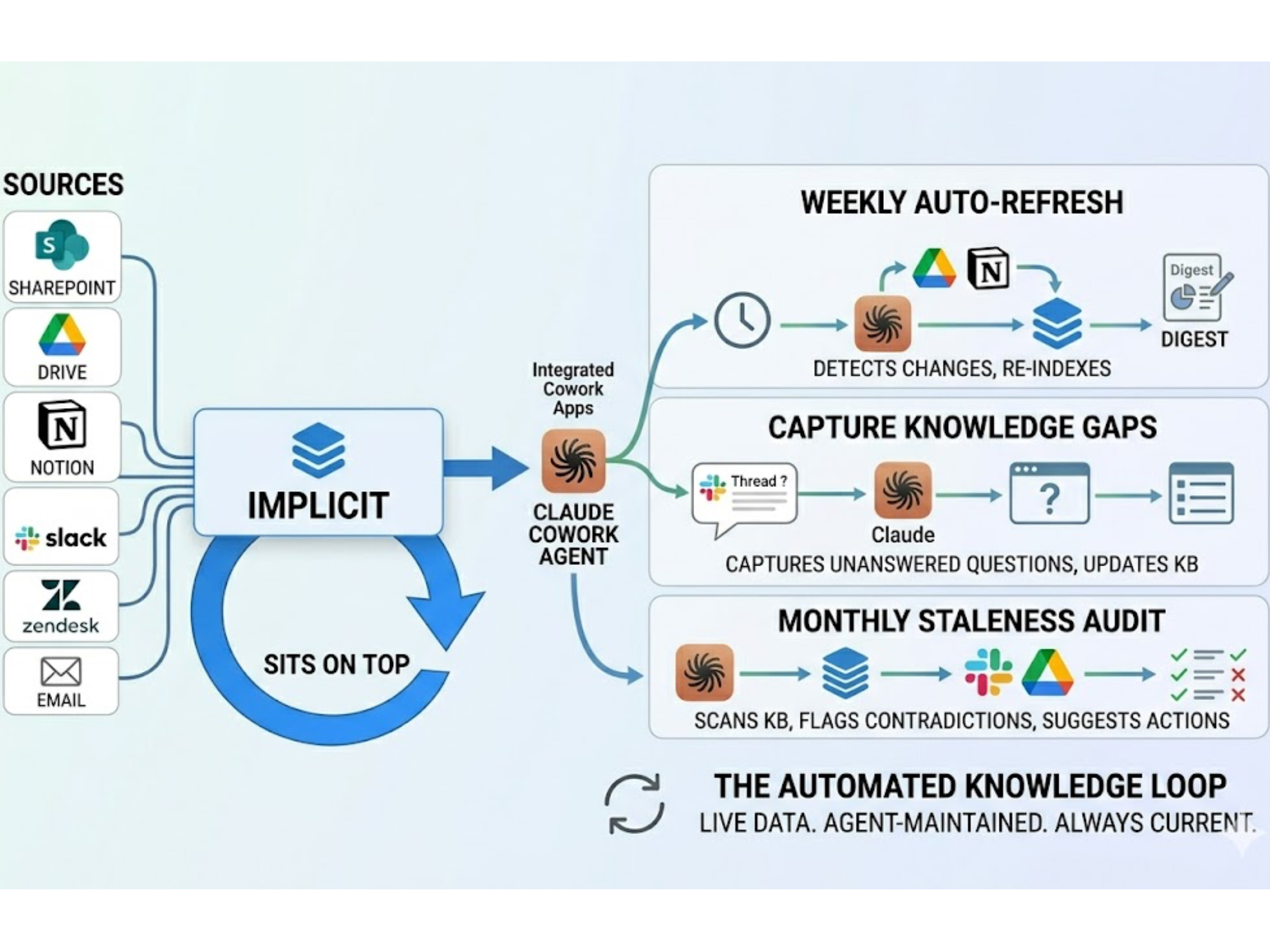
The operating model: Connect → Understand → Orchestrate
Connect
Unify what you really have: PDFs, wikis, tickets, runbooks, change logs, and the unprintable tribal knowledge trapped in chat. De-duplicate, mark sources of record, and version the rest. The boring work of content hygiene is the secret engine of accurate AI.
Understand
Extract entities and procedures. Map relationships into an Operational Knowledge Graph: product ↔ component ↔ version ↔ effectivity; issue ↔ symptom ↔ test ↔ fix; policy ↔ audience ↔ approval. Wrap it in a controlled vocabulary (TDG) so your domain means the same thing everywhere. Assign owners to terms so drift has a place to go besides production.
Orchestrate
Route every question through GraphRAG. Retrieve with precision, assemble step-by-step guidance with citations, include version and timestamp, and expose confidence and freshness. When confidence is low, escalate with full rationale - no black boxes, no vibes.
Three micro-examples
- Support AI: “Why does login fail for ‘E+’ accounts?” GraphRAG links “E+” → “Enterprise Plus,” detects SSO policy, pulls v2.1, notes a breaking change last week, returns remediation steps with citations and a freshness flag. The answer doesn’t live in just one place. It’s stitched across policy, release notes, and KB.
- Ops AI: “Who approves a high-risk release?” The graph resolves “high-risk” to criteria in the change policy, includes the current roster of approvers from the directory, and outputs the exact gate sequence, with audit trail references. No more Slack archaeology.
- MRO AI: “Fault 27-51 on tail N12345.” The graph reads configuration, checks effectivity, maps to ATA Chapter 27, and outputs cited steps with torque specs and known pitfalls. The words on the page match the metal in the hangar.
Measure what matters (and what to do with it)
- Accuracy % (by intent cluster): Don’t average everything. Track the high-volume, high-risk intents separately. Sample weekly, label truth, and push misses back to taxonomy or content owners.
- Freshness score (by document & entity): Age and last-validated date are different. Use both. A brand-new policy that never got validated is less trustworthy than a three-month-old one with weekly confirmations.
- Coverage %: Which intents return high-confidence, cited answers? The delta between what users ask and what you can answer is your content backlog, not your model problem.
- Routed-with-context rate: Escalations should carry sources, rationale, and attempted steps. If they don’t, your handoffs are leaking time.
- FCR & time-to-resolution: The scoreboard. Pair improvements with the content or taxonomy changes that caused them so you can repeat wins on purpose.
Common pitfalls (and how to dodge them)
- Embeddings-only search: Fast to start, fast to drift. Add TDG and source-of-record flags before you scale usage.
- Tag soup: If your taxonomy isn’t versioned and owned, it will dissolve into synonyms with bruised egos. Nominate stewards and write the change policy.
- Answer theater: Citations that don’t resolve to a source of record are just vibes with footnotes. Fix it at ingestion time.
A pragmatic 30-day plan
Week 1
Inventory & sources of record: Build a truth table: which repository wins when conflicts arise? Retire dupes; annotate the rest.
Week 2
TDG v0 & ownership: Define core entities and synonyms. Name owners. Publish a two-line policy for adding/changing terms.
Week 3
Extract & map: Lift entities/steps from your top five intents and wire them into the graph. Validate with SMEs using live examples, not meetings about meetings.
Week 4
Pilot + analytics: Turn on GraphRAG for one intent cluster. Label 25 answers. Review accuracy, freshness, coverage every Friday with content owners and term stewards.
Bottom line
RAG retrieves. GraphRAG + a Taxonomy-Driven Graph governs. When language and relationships are explicit, AI stops guessing and starts guiding (with receipts).