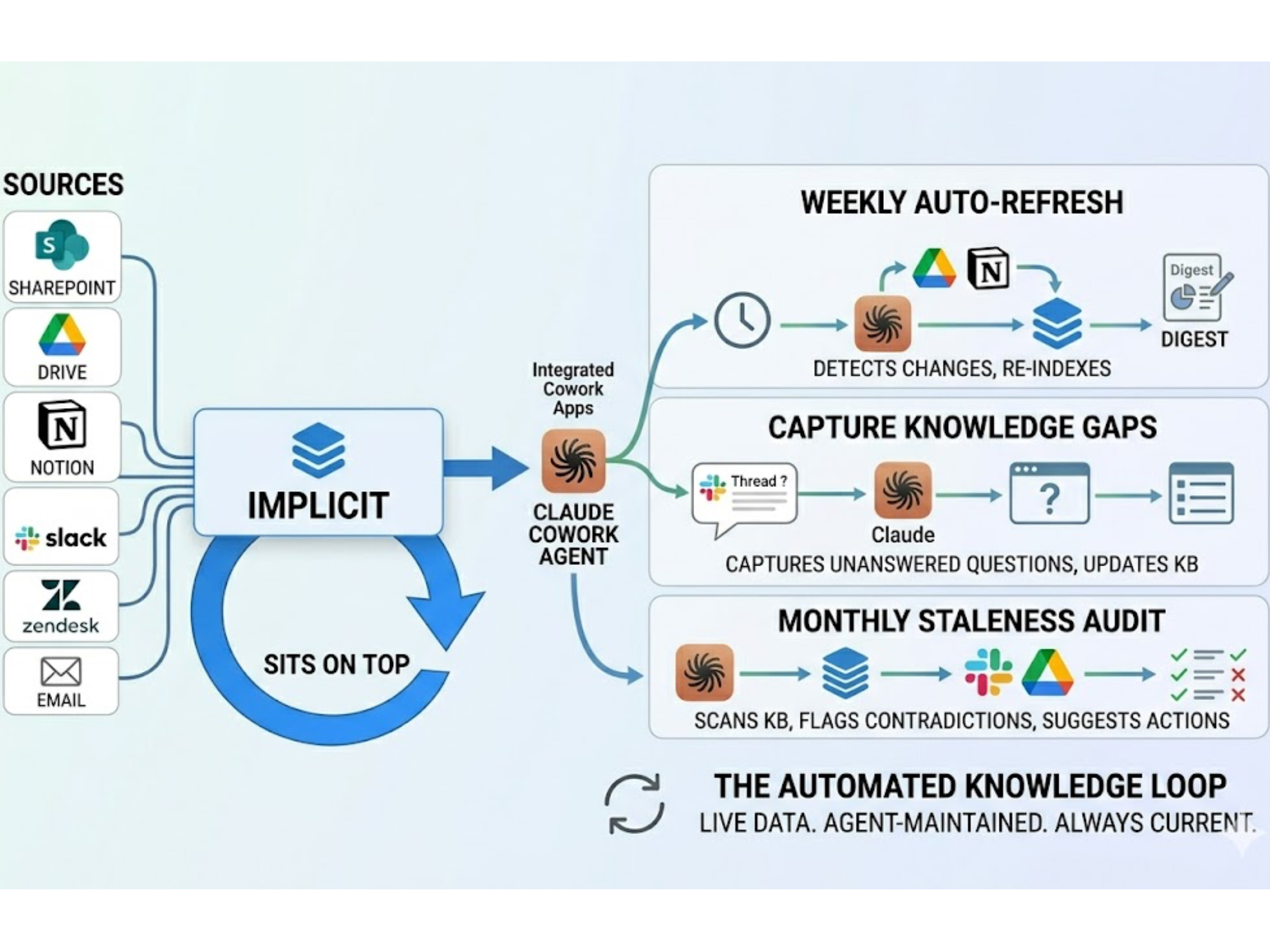
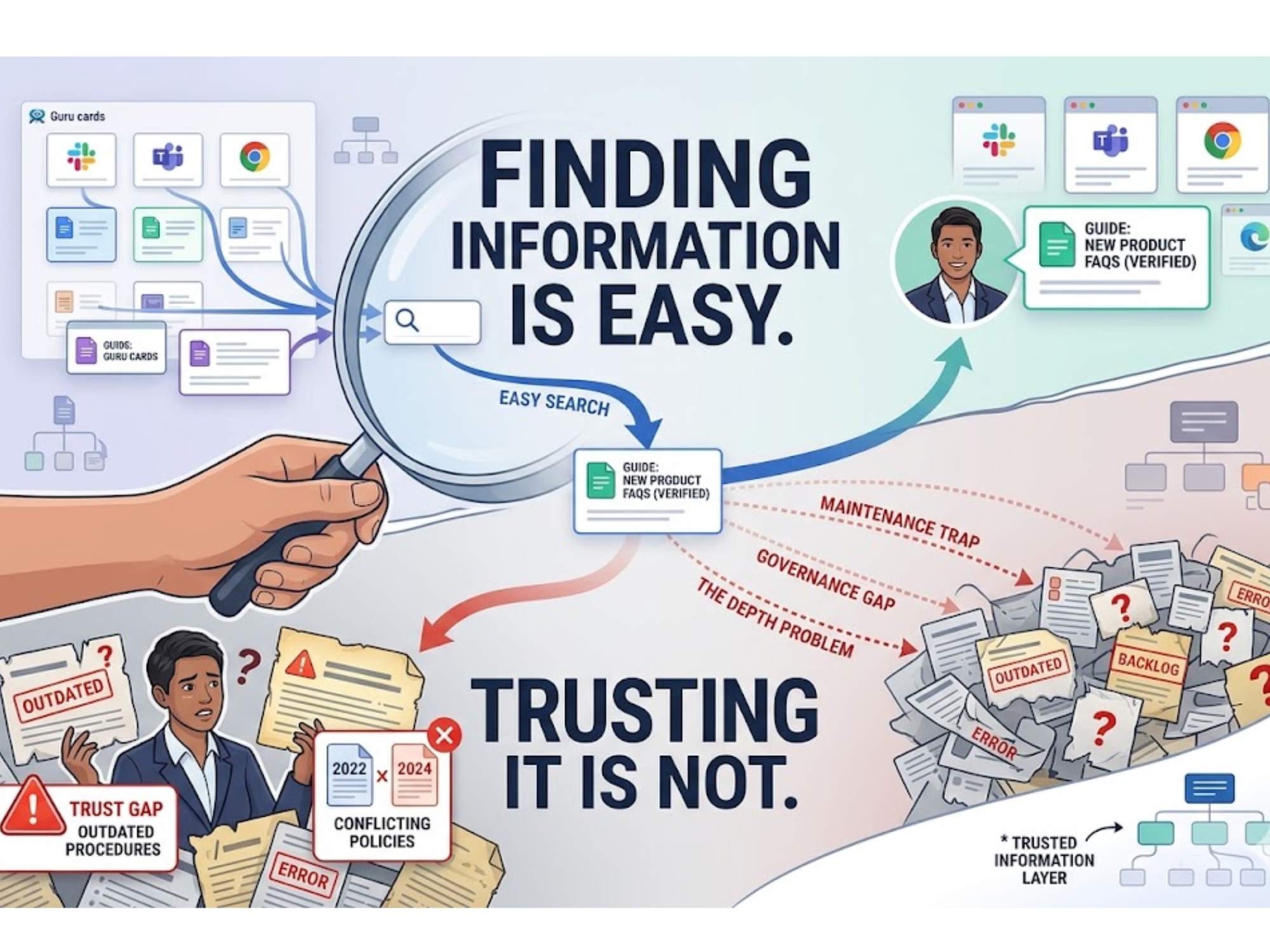
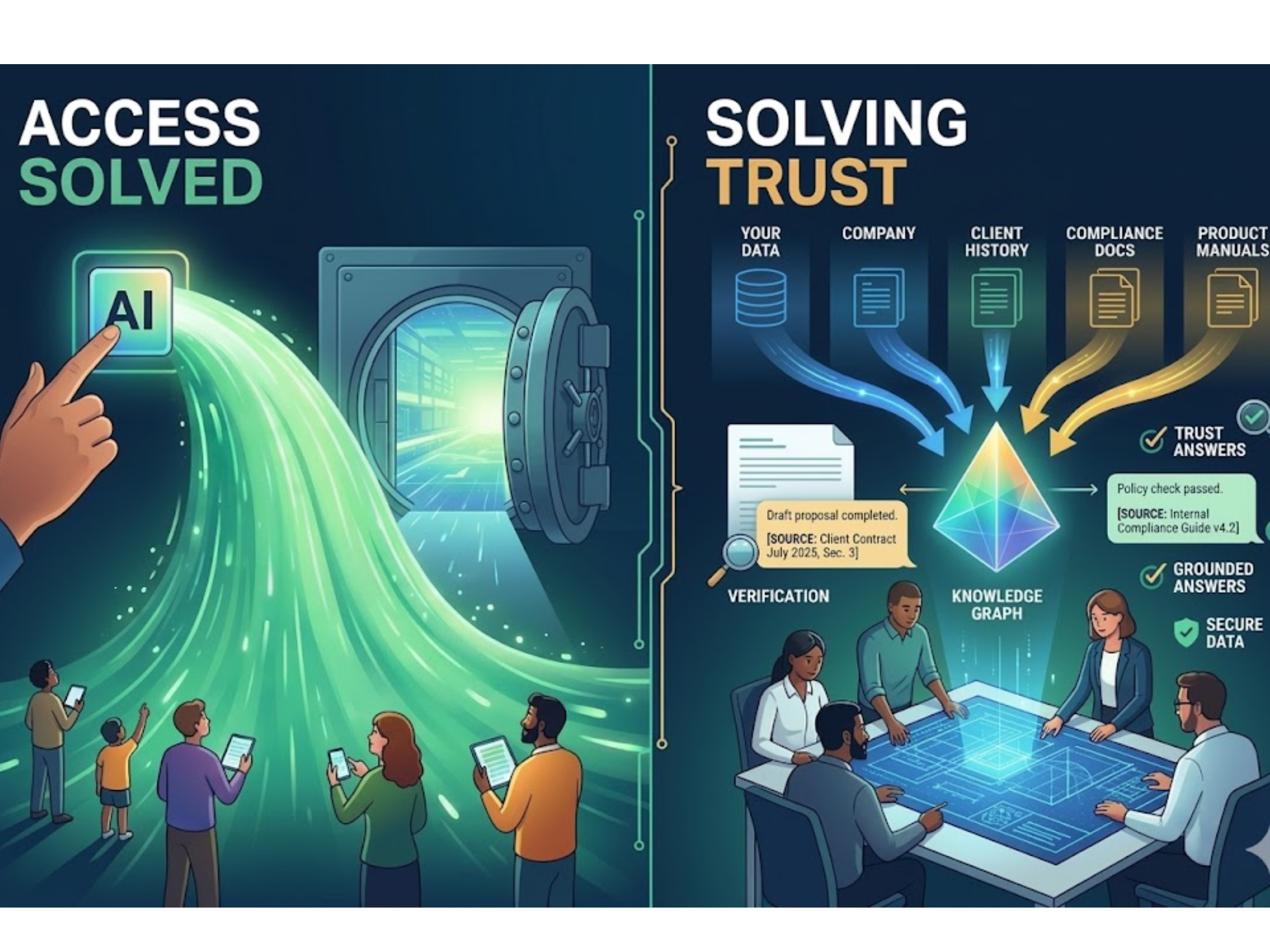
.svg)
Vertical AI Eats Accuracy for Breakfast

Generative AI models trained on the public internet are dazzling conversationalists, yet they are infamous for bluffing when the questions turn technical or complex.
Generative AI models trained on the public internet are dazzling conversationalists, yet they are infamous for bluffing when the questions turn technical. Over the past year a wave of peer-reviewed studies has shown that vertical approaches (GraphRAG, Agentic RAG, and domain-tuned Retrieval-Augmented Generation) close that accuracy gap in a big way. Below is a look at the latest numbers from five industries that cannot afford guesswork.
Evidence Across Critical Verticals
The pattern is consistent. Whether you are torque-spec hunting on a Boeing line, triaging a zero-day exploit, or guiding an agent through a multi-step software fix, vertical RAG stacks add 20–40 points of accuracy and lop off a healthy slice of hallucinations.
You can read more on this topic by downloading our ebook: The High-Stakes AI Playbook.
Why the Vertical AI Recipe Works
Structured knowledge beats fuzzy lookups
A graph encodes part-of, causes, and depends-on links that a cosine-similarity retriever cannot see. When the maintenance graph says hydraulic-pump → torque-spec 380 Nm, the model stops improvising.
Agents validate their own homework
Agentic RAG turns the model into a mini project manager: break the query, fetch precise chunks, cross-check sources, and reject anything fishy. That loop mimics what senior support engineers already do—just at GPU speed.
Domain knowledge leaves less room for error
A manufacturing knowledge base contains spindle speeds, not cat memes. Tighter scope frees up the LLM context window for actual reasoning instead of filler text.
Takeaways for Mission-Critical Teams
1) Aviation and Aerospace
If a wrong answer grounds a fleet or, worse, risks safety, GraphRAG’s 91 % exact-match should be your new minimum bar. Start with a component and fault graph, then add HybridRAG for explainability.
2) Cybersecurity
Threat intel changes hourly. Real-time GraphRAG lets analysts query live logs and intel feeds while tracing relationships between CVEs, malware families, and assets. Faster triage means fewer late-night war rooms.
3) Complex Product Support and Software
LinkedIn’s support graph proves that converting tickets, release notes, and call notes into a knowledge graph slashes handle time. Even if your corpus starts as messy PDFs, graph-first cleaning pays back quickly in CSAT.
4) Manufacturing
Studies show a simple fine-tune on plant jargon lifts accuracy, but adding RAG on top adds another two points. When your assembly line rides on correct torque and temperature ranges, those two points are expensive defects avoided.
Getting Started Without Breaking the Tooling Budget
Inventory your “single source of truth.”
Manuals, configuration tables, and historical Jira tickets are gold.
Graph first, vectors second.
You can always add embeddings for long-form passages later.
Track hallucinations explicitly.
It is not a solved problem until you can watch the metric trend toward zero.
Pilot an agent on one workflow.
Let it critique responses before you trust it to file purchase orders.
Bottom Line
General-purpose LLMs charm users, but they flatline in the face of high-stakes, industry-specific questions. The data above shows that vertical AI (GraphRAG, Agentic RAG, and domain-tuned retrieval) does not merely nudge accuracy. It throws the needle off the chart.
If your roadmap still relies on a one-size-fits-all chatbot, consider this your friendly nudge to get specialized before the competition eats your lunch - and your accuracy metrics for dessert.